I’ve been thinking about binary neural networks lately, and specifically how to do it without computing full precision gradients.
Broadly, there are two camps in binary neural networks. The most prominent (and effective) way to train binary neural networks is to keep the weights in full precision and binarise during forward pass. I’d say BitNet and ReactNet falls under that camp. The problem is of course that you are not taking advantage of the binary weights during the backward pass. Most binary NNs are motivated by the need for fast inference, not training, so full precision backward passes are not generally considered a problem. In fact, keeping latent full-precision weights (i.e non-binary weights) in memory during training is a tried-and-tested technique to train binary neural networks that don’t suck.
But, Shibuya et. al has been doing research on training binary neural networks without keeping a copy of the weights in full-precision in memory. They had an ICLR 2024 submission that unfortunately didn’t get accepted, and then a more recent paper titled Binary Stochastic Flip Optimization for Training Binary Neural Networks. They still use real-valued gradients, but they keep the weights binary throughout the training. The core idea is very intuitive:
Imagine a neural network with binary weights (0 and 1)
The activation function is a sign() function. This is of course not differentiable. So you use a straight-through-estimator (STE) as an approximation. Essentially, you pretend that you were using a hard-tanh as an activation function and compute the gradients as if you were using this tanh activation instead of sign()
The gradient computation proceeds normally – for a weight matrix W_l from layer l, you will have real-valued gradients. Let’s call this gradient matrix G_l
If we were using standard real-valued SGD, the weight would be updated as

Where
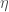
But you want to keep the weights W_l binary. If you add real-valued gradients to binary W_l, the updated weights will be no longer binary.
The authors get around this problem by simply binarising -G_l. Positive gradient values will be replaced by 1 and negative values will be replaced by a 0
But you can’t just add the binarised gradients to the weight matrix. That would be conceptually equivalent to having a learning rate of 1! That’s too high! And since the gradient matrix is now binary, there’s no concept of a “learning rate”.
Remember, G_l is now a binary matrix, and tells you what the updated weight matrix would look like. Conceptually, if our learning rate (whatever that means – bear with me) was 1, we would just add the gradient matrix to the weight matrix. In our case, instead of adding the gradient matrix to the weights, we would just replace the weight matrix with the gradient matrix. This is the ugly side effect of using binary weights.
Let that sink in. When your gradients are binarised, you can’t “add” the gradient to the weight. The gradient value is going to be either a 1 or a 0. Your weight too is going to be either a 1 or a 0. Your decision is to either match the gradient value or not to match it. For example, if the weight is 0 and the gradient is 1, you have no option but to set the weight to 1 – because that’s what the gradient is telling you to do in order to minimise the loss!
But if we do what the binarised gradient tell us to do, we’ll be flipping our binary weights all the time. In other words, our learning rate is too high! But what does it mean to have a “low” learning rate when the gradient matrix just contains 1s and 0s?
The authors of Binary Stochastic Flip paper suggest that we use a binary mask and do an element-wise multiplication with the gradient matrix. This way, you can select a subset of the gradient matrix to be applied. In other words, instead of setting all the weights according to the gradient matrix, we update only a fraction of the (eg: 10%) of the weights to match the gradient matrix. When the learning rate is “1” (or when it is “maximum”), the mask is a tensor with every element set to 1. To user a lower learning rate, the mask matrix is created in such a way that it will only have a few ones.:






The paper even mentions that setting the Mask randomly works rather well.
In PyTorch, I think it will look something like this:
class HyperMaskOptimizer(Optimizer):
def __init__(self, params, delta=1e-3):
"""
Args:
params: Model parameters (binary weights in {0,1})
delta: Probability for random mask (δ_t in paper)
"""
defaults = dict(delta=delta)
super(HyperMaskOptimizer, self).__init__(params, defaults)
self.delta = delta
def step(self, closure=None):
for group in self.param_groups:
for param in group['params']:
grad = param.grad
current_weights = param.data.clone() # w_{t-1} in {0,1}
target_weights = (-grad >= 0).float() # w*_t in {0,1}
mask = torch.bernoulli(torch.full_like(grad, self.delta))
mask_not = 1 - mask # m̄_t (NOT operation)
new_weights = (mask_not * current_weights) + (mask * target_weights)
param.data.copy_(new_weights)
I wasn’t able to reproduce the numbers that the authors reported. Here’s my implementation. My 4-layer perceptron achieved only an unimpressive 33% test accuracy on MNIST after training for 200 epochs. Unfortunately the paper does not mention a reference implementation for me to cross-check with. I’ve reached out to someone whose name matches with that of the first author on LinkedIn. If I’m lucky, they’ll open source their implementation.
Meanwhile, if you can spot bugs in my snippet, please comment on the Github gist (or here) 😀
